OpenVXI: Fostering VoiceXML via Open Source
By Brian Eberman
Continued from page 1...
OpenVXI prompting, telephony, and recognition interfaces were designed with VoiceXML in mind. . VoiceXML is an inherently synchronous language. Although there is an event model within VoiceXML, these events are only propagated when the VoiceXML interpreter makes its next traversal through the form-filling algorithm or makes a page transition. Thus, all the platform interfaces are synchronous and don't have the added complexity of a callback mechanism.
All asynchronous event handling is delegated to the underlying platform implementations for telephony, prompting, and recognition. Telephony event handling, URL fetch timeouts, asynchronous audio delivery and a host of additional events must be handled within an implementation of these platform components. We have found this model to be effective and flexible with SpeechWorks technology, Dialogic technology, and VoIP technology. Based on discussions, users of the toolkit have done integrations to S.300, SAPI, and a number of proprietary recognizer and platform interfaces.
1.1 PROMPTING OUTPUT
VoiceXML 2.0 prompting is considerably more complex than playing a set of audio files and TTS prompts. The prompting implementation should be able to:
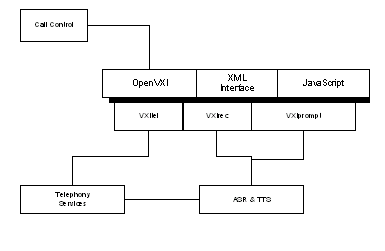
Figure 2: OpenVXI Platform Interfaces and Architecture Integration Model
- Download audio and TTS from the Internet.
- Support fetchaudio if no other prompt is playing.
- Support SSML including interleaving TTS and audio for playback.
- Handle fetch failures and swapping to TTS when audio fetches fail.
Generation of all prompting with the OpenVXI is delegated to a single component due to the synchronous nature of the interpreter and for the ability to better leverage SSML When the interpreter encounters a prompt component that contains SSML, it delegates the generation of the entire prompt to the component. The Queue method of the interface provides this delegation. Note that this model is directly supported within an MRCP implementation.
The Queue method takes the URL source, possibly the text, and a MIME type that specifies how to generate the prompt. Queue then blocks until the data is fetched, or the stream is started so that any errors can be returned back to the interpreter. The Queue method must then invoke any of its underlying services including URL fetching and TTS generation to start the generation of audio for the prompt.
Fetchaudio, or music on hold, is another tricky area for the interfaces. The semantics of fetchaudio are that the indicated URL should be used for playing audio, if no other audio is currently playing. Since the semantics for this segment are different from the standard audio segments, we chose to separate it out as a separate play function.
SSML is a new specification and few text-to-speech vendors fully support the specification. Many implementations of the prompting engine will have to provide a way to split the SSML into segments and queue it separately into audio and TTS until multiple engines support SSML.
1.2 RECOGNITION INPUT
The rec component is responsible for processing user input. An implementation of the rec interface should be able to:
- Support recognition against multiple parallel grammars.
- Allow for both speech and DTMF entry.
- Return one or more (n-best) recognition hypotheses with corresponding confidence scores.
- Implement the 'builtin' grammars for simple types (e.g. date, time, and currency).
- Return the waveforms from recognition utterances and recordings.
Recordings in VoiceXML may be terminated by either DTMF or an application-specified duration of silence. These parameters are passed in to the Record function of the rec interface via properties. This component must, therefore, incorporate end-of-speech detection. Likewise, DTMF grammars are supported with application-specified inter-digit timeouts and termination criteria. This requires that the rec component communicate with the hardware layer to collect DTMF, audio, and possibly hang-up or other events. Each recognizer and hardware integration will manage this complexity differently. The OpenVXI does not make any assumptions about how the rec component implements timers, links to the recognizer, or interacts with the hardware layer. Instead, the developer is expected to pass any resources (e.g. hardware channel handles) to the rec component during its initialization.
Grammars may be specified within VoiceXML directly within the grammar element or indirectly. In the second case, the text serves a dual purpose of generating text-to-speech enumerations and speech grammars. The corresponding grammar must be generated within the rec component. The W3C SRGF allows grammars to include subgrammars from specified URIs. This may require passing an Internet access component instance to the rec component on initialization. Because of the tight coupling of grammars and URI handling in the W3C specifications, we chose to delegate all fetching of grammar URLs to the recognizer interface. The implementation of the rec component must fetch the desired grammar URI and any dependent URIs that are included via the grammar import directive.
In order to enhance the abstraction of the grammar format, the next release will provide a mechanism where the platform can construct the grammars internally for options and menu grammars and then return a handle to the interpreter for that grammar. In previous releases, the OpenVXI generated an SRGS grammar for these cases and required the platform to be able to handle the particular version of SRGS that the interpreter was using.
Recognition results are returned using the W3C Natural Language Semantic Markup Language (NLSML). This standard is targeted at complex grammars that may return multiple pieces of data with one utterance. For instance, the user might say "I'd like to fly from Boston to San Francisco on the Fourth" with the recognizer receiving both data directly specified by the user and determined by the grammar: { DEPART='BOS'; DESTINATION='SFO'; DATE='20010604'; AIRLINE='any'; }.
The NLSML specification is the only standard in the Voice Browser working group set that defines a return format for a recognition result, so we used this to produce a standard return interface. NLSML is also very convenient for distributed models that may be considered in a multi-modal implementation and is directly required and supported within MRCP.
Recognition during transfer requires an extension to the OpenVXI 2.0.1 interfaces. Because this operation requires that grammars be loaded and activated before the transfer occurs, a recognition or hot-word based transfer is naturally part of the recognition interface.
Continued...

back to the top

Copyright © 2001-2003 VoiceXML Forum. All rights reserved.
The VoiceXML Forum is a program of the
IEEE Industry Standards and Technology Organization (IEEE-ISTO).
|



