W3C Natural Language Semantics Markup Language
(Continued from Part 1)
[NOTE: This article is published with the express permission of Unisys Corporation. Unisys
Corporation retains ownership of the copyright of this article.]
Advantages of NMSML
Flexible Connection between the ASR Interpreter and the VoiceXML Interpreter
NLSML makes the connection between the speech recognizer and the VoiceXML browser much more flexible. This is especially important for multi-modal applications because speech isn't the only form of input for these applications. For example, in a multi-modal application, multiple input interpreters might produce independent NLSML interpretations of the input they've received, as the results of simultaneous speech and pointing events. A multi-modal integration component could integrate these two representations so that only one unified representation of the user's input is supplied to the VoiceXML interpreter.
Another way in which NLSML can add flexibility to the dialog processing architecture is by making it easier to use a third party grammar library that the developer is not able to modify. NLSML output from the third party grammar could be reformatted with an XSLT stylesheet to be compatible with the VoiceXML application. For example, if a third party Social Security number grammar returns an element called "SS_no", but the VoiceXML application has a field called "social_security_number", it would be easy to transform the grammar's output into the appropriate format for the VoiceXML application by writing a stylesheet that maps the NLSML output from the recognizer to the NLSML input expected by the VoiceXML application.
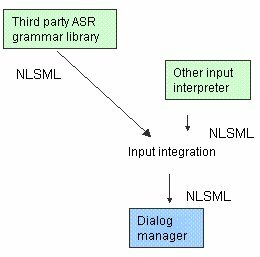
The flexibility provided by NLSML can be seen graphically in the following diagram, where two input interpreters, a speech recognizer and another input interpreter (for example, a handwriting recognizer) provide NLSML input which is combined into a single integrated NLSML representation in an input integration phase and then passed to the dialog manager.
Richer Information about Input Processing
NLSML can represent richer information about the input process than is typically available in ASR output. This includes, for example, low-level information about the time that an input was actually produced. Having this low-level information could be especially useful in multi-modal applications, which might need to know exactly what the user was looking at on the display when a particular utterance was produced. Timestamps are available for the entire utterance as well as for individual words. Here's an example using the NLSLM <input> element that shows how timestamps and confidences for individual words can be expressed.
<input>
<input mode="speech" confidence="50"
timestamp-start="2000-04-03T0:00:00"
timestamp-end="2000-04-03T0:00:00.2">fried
</input>
<input mode="speech" confidence="100"
timestamp-start="2000-04-03T0:00:00.25"
timestamp-end="2000-04-03T0:00:00.6">onions
</input>
</input>
|
Common Data Model among Components
ASR grammars conforming to the W3C Speech Recognition Grammar Specification are not required to describe their expected output, and VoiceXML 2.0 processors are not required to describe their expected input, leading to the potential for mismatches. Mismatches between the ASR output and the voice browser input can be difficult to detect. Although sometimes these mismatches will result in errors, at other times they will only result in unexpected behavior in the application. Future specifications could potentially include an ability to specify a common data model among the ASR interpreter, the NLSML interpreter, and the Voice Browser. One way of doing this, for example, would be to make use of the W3C's XForms specification. With a common data model, mismatches between expected data structures could be easily detected at compile time.
Current use of NLSML
Currently, NLSML is not heavily used for speech applications. In most platforms, ASR output is linked to the voice browser that it supplies input to in a tightly coupled fashion. That is, the output from the ASR goes directly to the voice browser, and isn't represented in NLSML. This is adequate for most current applications because
- Ad hoc semantic representations are sufficient to support most applications.
- Voice browser platforms are tightly integrated with specific ASR's and most VoiceXML applications and grammars are written in parallel so that tight coordination is possible.
- Validation of the output of a speech recognizer with respect to the VoiceXML fields that it fills is also not performed in current VoiceXML, so it's not possible to take advantage of the fact that output in the form of NLSML can be validated.
As multi-modal applications become more widespread and applications that make use of the additional capabilities of NLSML start to be deployed, we'll start seeing more widespread use of NLSML.
Future Directions for NLSML
There are many potential directions for future versions of NLSML which would allow it to support richer and more complex input. Here are three examples of possible future NLSML work:
1. Representing multiple references to the same item. User's natural language utterances often contain multiple references to the same item. It's obviously important to be able to link them up. This is especially important if references to the same items, or different items with the same name, occur in multiple dialog turns. Without this kind of bookkeeping, serious mistakes can be made. For example in an airline application, the user might end up with more or fewer flights than desired because the system failed to keep track of when the user was talking about a new flight and when the user was referring to a previously mentioned flight.
2. Representing multi-modal input. Although NLSML was originally intended to be usable to represent inputs other than speech, it was actually developed primarily with speech in mind. In order to be used to represent non-speech input such as text input or handwriting, it needs to be reviewed with respect to the requirements of these other modalities.
3. Interaction with other semantic standards: Other potentially valuable extensions to NLSML would include exploring how NLSML could work with emerging Semantic Web standards, such as RDF and web ontologies.
back to the top

Copyright © 2001-2002 VoiceXML Forum. All rights reserved.
The VoiceXML Forum is a program of the
IEEE Industry Standards and Technology Organization (IEEE-ISTO).
|



